깃으로 이동
시작하기에 앞서 지난번 코드의 결과물을 먼저 확인해보자.
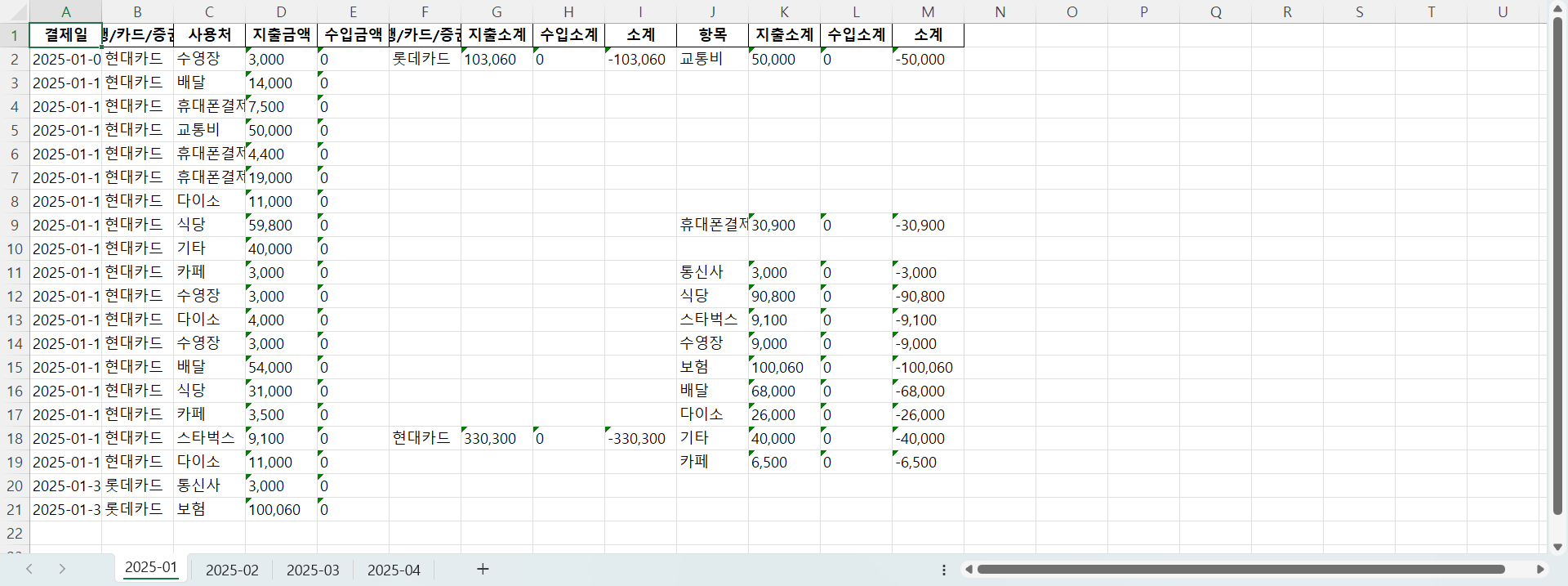
내가 원하는 산출물은 아래와 같다.
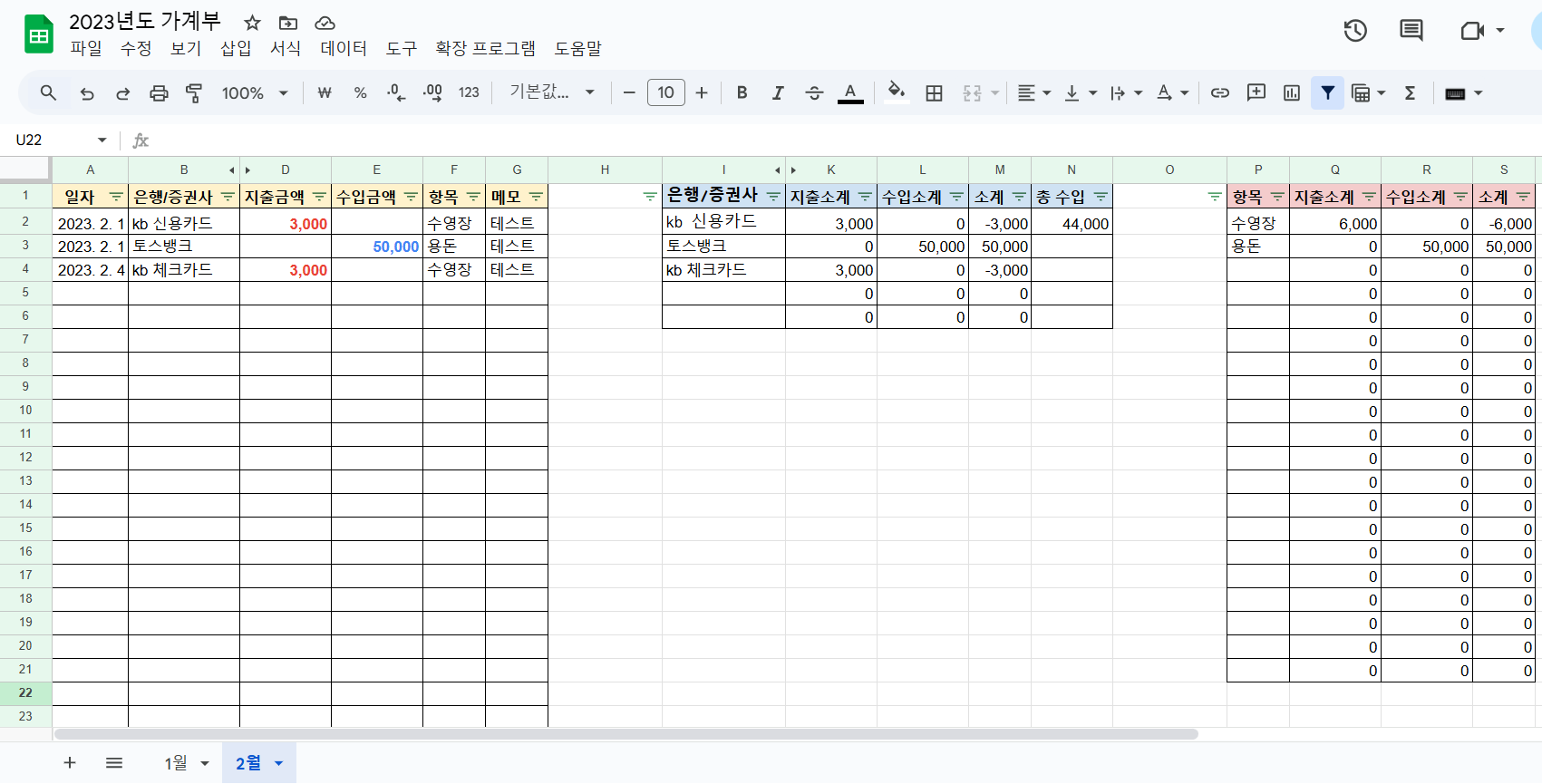
- 필수 항목 (결제일, 은행/증권사, 지출금액, 수입금액)
- 은행/증권사 소계 (은행/증권사, 지출소계, 수입소계, 소계)
- 항목 소계 (항목, 지출소계, 수입소계, 소계)
은행/증권사 소계와 항목 소계를 확인해보면 비어있는 셀이 많아 가독성이 떨어진다. 이를 원하는 산출물로 바꾸는 작업을 추가해야 한다.
Todo List
- 소계 그룹별 UI 수정
- 필수 항목, 은행 소계, 항목 소계 사이에 빈 셀 추가
- 소계별 빈 셀 제거
- 은행/증권사에 총 수입 추가
- UI 추가
- 헤더별 색상 변경
- 금액 오른쪽 정렬
- 행 너비 조절
- 내용이 있는 셀에 테두리 추가
소계 그룹별 UI 수정
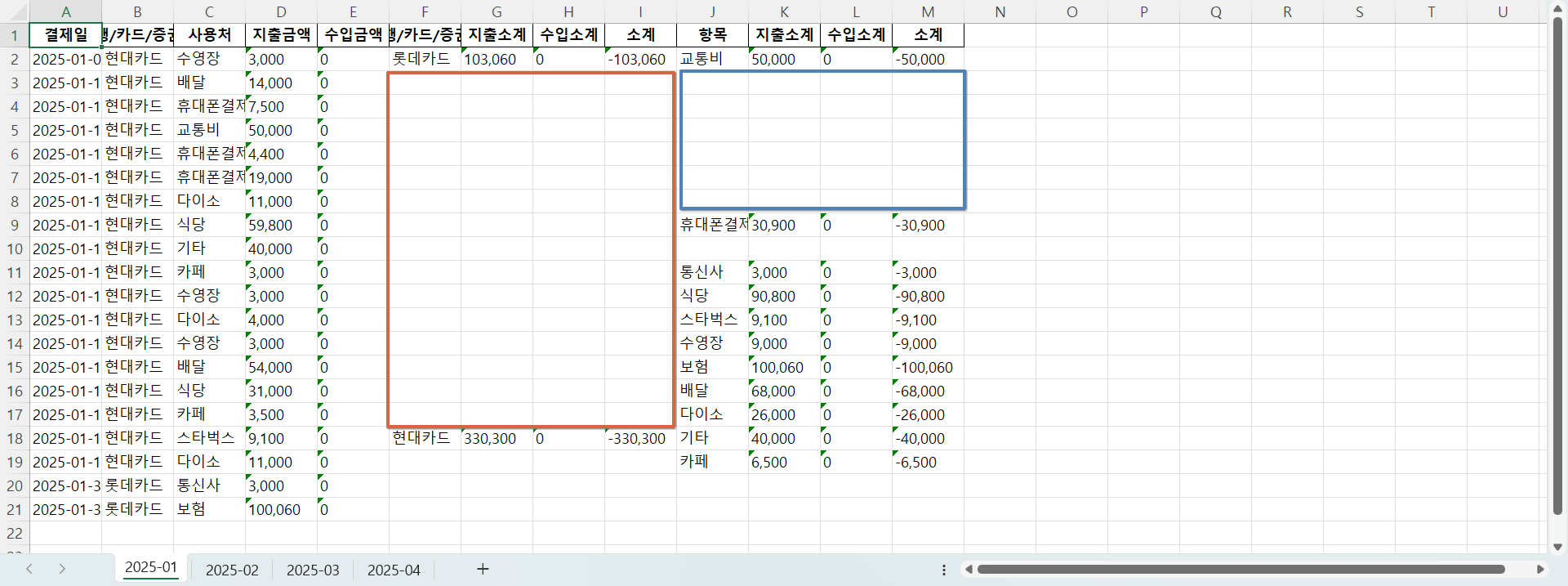
이렇게 보이는 원인 코드는 다음과 같다.
import pandas as pd
resultData = pd.concat([필수항목, 은행증권사소계, 항목소계], axis=1)
resultData.to_excel(writer, sheet_name=month, index=False)
concat은 DataFrame을 행, 열 기준을 선택해 병합 할 수 있다고 한다. 나는 열 기준으로 병합할 때 각 소계 그룹별 길이가 달라서 발생한 문제였다.
| axis=0 | axis=1 |
|---|---|
| 데이터를 아래로 합침 (행 기준 합치기) | 데이터를 옆으로 합침 (열 기준 합치기) |
| 데이터를 추가할 때 사용 | 컬럼이 다른 데이터를 추가할 때 사용 |
- 필수항목의 열 = 21
- 은행증권사소계의 열 = 2
- 항목소계의 열 = 11
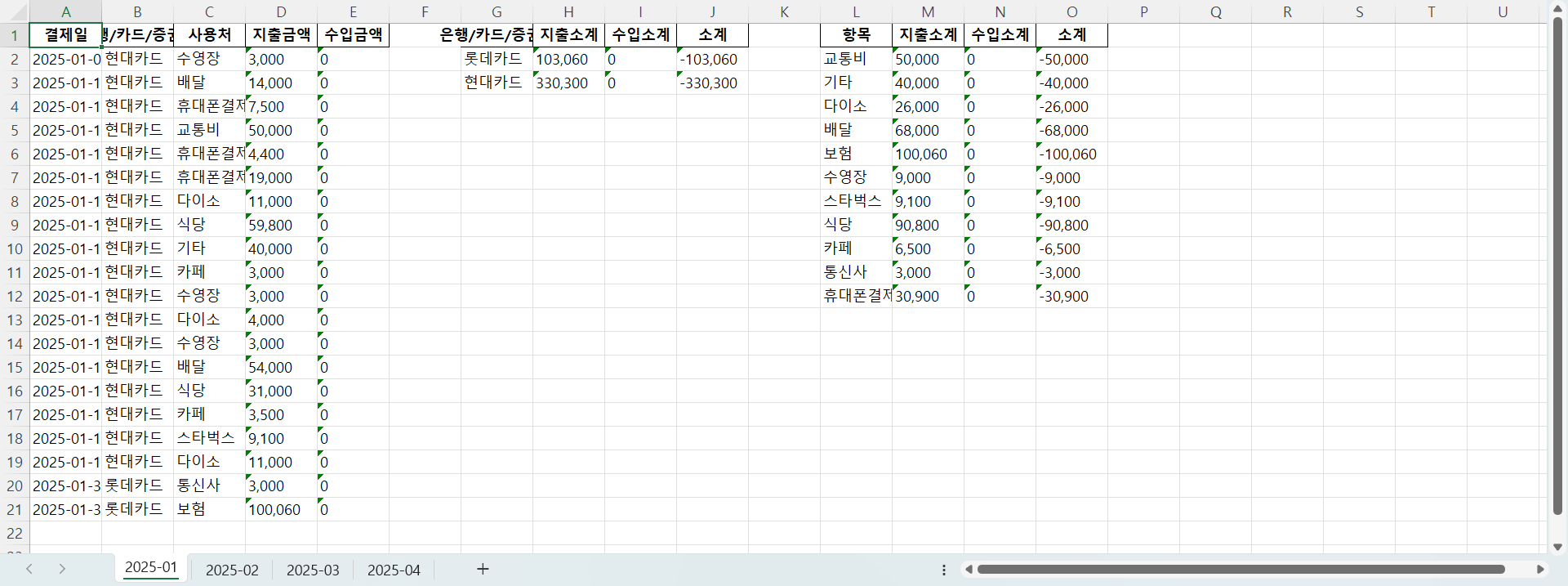
그래서 이렇게 각 소계 그룹을 1열부터 시작하게 하려면 to_excel을 이용해 시작 행과 열을 지정한 후에 병합하는 것이 좋다.
참고로, to_excel을 이용해 시작 행과 열을 지정할 경우 startcol 파라미터로 각 그룹을 구분하기 위한 공백 셀을 추가할 수도 있다.
group.to_excel(writer, sheet_name=month, index=False, startrow=0, startcol=0)
mid_data.to_excel(writer, sheet_name=month, index=False, startrow=0, startcol=6)
end_data.to_excel(writer, sheet_name=month, index=False, startrow=0, startcol=11)
resultData = pd.concat([group, mid_data, end_data], axis=1)
은행/증권사에 총 수입 추가
처음에는 ‘총 수입’ 컬럼만 추가하면 간단하게 끝날 줄 알았다. 아래는 생각한 대로 만들었던, 제대로 동작하지 않는 코드이다.
with pd.ExcelWriter(document.EXPORT_DOCUMENT+'/'+output_file_name, engine='openpyxl') as writer :
for month, group in excel_data.groupby('월') :
# 은행/카드/증권사별 소계 계산
# (생략)
# 항목별 소계 계산
# (생략)
# 데이터 포맷 맞추기
mid_data['지출소계'] = format.numberFormat(mid_data['지출소계'])
mid_data['수입소계'] = format.numberFormat(mid_data['수입소계'])
mid_data['소계'] = format.numberFormat(mid_data['소계'])
mid_data['총 수입'] = 0 # 테스트용 임시 값
# (생략)
mid_data[’총 수입’] = 0 으로 작성하면 모든 행에 0이 들어가서 ‘소계’의 합을 표현하는 열이 되지 않는다.
문제는 두 가지 있었다. 하나는 “소계 그룹별 UI 수정”에서 언급한 열이 다른 두 DataFrame, 나머지 하나는 이미 numberFomat(임의로 생성한 숫자 , 표시 함수)를 적용해 for할 때마다 각 numberFormat한 문자열을 합친 문제였다.
- 은행/카드/증권 행 ~ 소계 행은 1 이상의 행이 발생 (헤더 포함)
- 총 수입 행은 반드시 2개의 행이 발생 (헤더 포함)
- 결론 : 결과 행이 다른 컬럼을 각각의 DataFrame으로 만들어
concat시 axis=1 값을 추가하는 것이 데이터 관리에 용이하다.
with pd.ExcelWriter(document.EXPORT_DOCUMENT+'/'+output_file_name, engine='openpyxl') as writer :
for month, group in excel_data.groupby('월') :
# 은행/카드/증권사별 소계 계산
# (생략)
# 항목별 소계 계산
# (생략)
# 데이터 포맷 맞추기
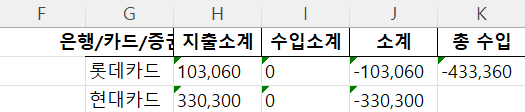
total_income = mid_data['소계'].sum()
mid_data['지출소계'] = format.numberFormat(mid_data['지출소계'])
mid_data['수입소계'] = format.numberFormat(mid_data['수입소계'])
mid_data['소계'] = format.numberFormat(mid_data['소계'])
total_income = format.numberFormat(total_income)
total_sum = pd.DataFrame(columns=['총 수입'], data=[total_income])
mid_data = pd.concat([mid_data, total_sum], axis=1)
#(생략)
- total_income : 다른 행의 numberFormat을 유지하고 싶으니 먼저 총 수입 값을 구한다.
- total_sum : mid_data와 합치기 위한 행이 다른 DataFrame 추가
- concat : axis=1을 이용해 mid_data와 total_sum 데이터를 열 기준으로 합친다 (mid_data 데이터 옆에 total_sum 데이터 합침)
짧은 회고
최근 개인적인 일로 바쁘게 지내다가 오랜만에 파이썬을 들여다 봤다. 아무래도 파이썬을 배우는 단계인데 쉬었다 다시 봤더니 “분명 여기까진 잘 동작하는 거 확인했는데, 왜 이렇게 되지?” 하는 코드가 있었다. 저장 전에 ctrl+Z를 눌렀던 것 같다.
아주 간단한 기능을 만들면서도 반복되는 코드가 점점 늘고 있다. 애초에 변수명 규칙도 통일하지 않은 상태에서 작업하다 보니 혹시 이 글을 읽을 다른 분들도, 나중에 볼 나도 헷갈릴 것 같다. 반복되는 코드라도 줄이기 위해 자바의 클래스처럼 파일별로 함수를 분리해뒀다. 기획했던 모든 일을 마치면 변수명 통일과 리팩토링도 고려해야겠다.
글의 호흡이 길어져 UI 추가에 대한 내용은 다음 게시글로 작성하려고 한다. 헤더별 색상 변경은 간단하게 구현이 가능했지만 다른 내용은 pandas 함수와 인터넷을 조금 더 찾아봐야겠다.