깃으로 이동
파이썬을 처음 접하고 pandas 까지 연습해봤을 때 가계부 만들기가 아주 쉬울 거라고 생각했다.
내가 사용하는 카드사에서 엑셀 파일을 내려받고 pandas로 파일을 읽었더니 오류의 향연이라 의외였다. 엑셀 파일 열기는 일단락 지었고, 다음으로 고민해야 할 부분이 생겼다.
데이터 전처리
pandas가 아주 편리한 모듈이긴 하지만 서로 다른 카드사의 데이터를 dataFrame에 합칠 때 파일 내의 헤더를 알아서 구분해서 합쳐주진 않는다.
카드사별 헤더
| 카드사 | 헤더 명칭 |
|---|---|
| 현대카드 | - 결제일 - 이용일 - 입금경로 - 상품명 - 이용하신곳 - 이용금액 - 원금 - 수수료 - 연체료 |
| 국민카드 | - 이용일 - 이용\n시간 - 이용\n고객명 - 이용카드명 - 이용하신곳 - 국내이용\n금액\n(원) - 해외이용\n금액\n($) - 결제방법 - 가맹점\n정보 - 할인금액 - 적립(예\n상)\n포인트리 - 상태 - 결제예정일 - 승인\n번호 |
| 롯데카드 | - 이용일자 - 이용시간 - 이용카드 - 이용가맹점 - 업종 - 이용금액 - 이용구분 - 할부개월 - 승인번호 |
| 기대하는 헤더값 | 결제일 (Y-m-d) 지출금액 수입금액 사용처 : 이용하신곳, 이용가맹점 은행/카드/증권사 ← 엑셀의 헤더 말고 다른 곳에서 데이터를 가져와야 함 |
이렇게 각 카드사별로 헤더값, 데이터 포맷이 다른 데이터를 기대하는 값으로 바꾸는 과정이 “데이터 전처리” 이다. 다시 말하면 데이터를 분석, 사용하기 쉽도록 정리하는 과정이다.
데이터 전처리 과정 (v1.0)
Python 사용이 처음이라 데이터 전처리를 쉽게 하고 싶었다. 이번에는 데이터 전처리를 이런 순서로 진행 예정이다.
- 파일명의 접두사 로 카드사 명칭을 추가 한다 (예:hd, kb, lt, lotte…)
- (내가 정한 요구사항에 의해) 은행/카드/증권사별로 정보를 구분할 수 있어야 하기 때문
- 카드사별로 헤더 시작 지점을 지정 한다
- 예) 현대=결제일, 국민=이용일, 롯데=이용일자
- 헤더 명칭 통일 (rename 예 : 이용일자, 이용일 = 결제일)
- 지출 금액, 수입 금액 헤더 추가
- 카드 승인 완료 상태인 경우 지출 금액
- 카드 승인 취소인 경우 수입 금액
- 날짜 컬럼인 경우 날짜 형식 통일 (Y-m-d)
- 금액 컬럼은 세자리마다 , 적용
어려웠던 과정
pandas의 read_excel로 읽히지 않는 엑셀 파일
- 이전 게시물에서 해당 내용을 다룬 적 있다.
[pandas] ValueError: Excel file format cannot be determined, you must specify an engine manually. - 병합된 셀이 없고 단순 표 형식이라면 read_html로도 데이터를 확인할 수 있다. 하지만 엑셀의 시트를 나누고 pandas에서 제공하는 기능을 활용하고자 한다면 이전 게시물을 읽는 것을 추천한다.
-
xlsx로 변환 시 파일 내에 표가 여러개인 경우 원하는 데이터를 어떻게 가져와야 하는지 고민이었다.
# 리턴 형식 비교 read_html -> list[DataFrame] read_excel -> DataFrame위 내용을 감안하고 read_html의 리턴 데이터의 len을 확인하면 표 개수를 확인할 수 있다. 마침 내가 원하는 표는 마지막에 있는 표라서 이런 코드를 만들어 html 형식의 엑셀을 xlsx 엑셀로 변환했다.
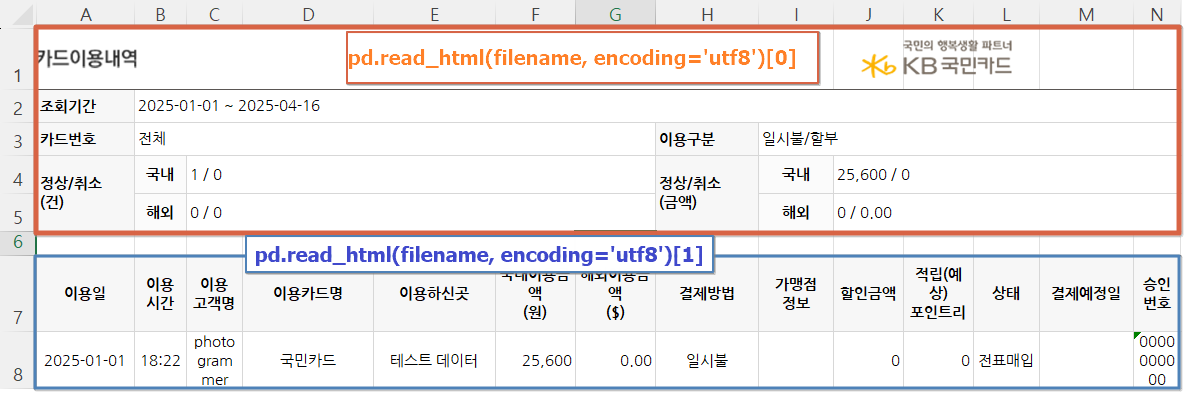
temp_file = pd.read_html(filename, encoding='utf8') # 마지막 테이블의 데이터 가져오기 df = temp_file[len(temp_file)-1] df.to_excel(filename+'x', index=False, engine='openpyxl') - 막상 구현해놓고 보니 간단했는데 이런 규칙이 있다는 것을 늦게 발견했다.
Unnamed:0 … 헤더
Unnamed: 0 Unnamed: 1 Unnamed: 2 Unnamed: 3 Unnamed: 4 Unnamed: 5 … Unnamed: 8 Unnamed: 9 Unnamed: 10 Unnamed: 11 Unnamed: 12 Unnamed: 13
파일을 read_excel로 읽는 데 성공했는데, 이번에는 헤더가 이상했다. 기대했던 값은 아니었다. 이를 이해하려면 우선 read_excel의 header 파라미터에 대해 짚고 넘어가야 했다.
read_excel 파라미터, header 짚고 넘어가기

- header 파라미터는 해당 파일의 헤더 위치를 int로 받는다.
파일에 헤더가 존재하지 않으면 header=None,
기본값은 header=0 - header=None 인 경우 모든 헤더가 Unnamed:{index}로 보인다
- header를 지정하지 않는 경우 0번 인덱스가 헤더로 설정
의미와 원인
의미Unnamed:0 = 0번째 인덱스의 행에 내용이 없음원인- header=None으로 지정 후 수동으로 컬럼을 지정하지 않은 경우
- header로 적용된 행에 실제 내용이 없는 경우
- 병합된 셀인 경우
header=None으로 지정한 경우
- 수동으로 헤더 이름 지정
import pandas as pd
df = pd.read_excel('file.xls', header=None)
df.columns = ['결제일', '지출금액', '수입금액', '사용처', '은행/카드/증권사']
header로 적용된 행에 실제 내용이 없는 경우 || 병합된 셀인 경우
- 헤더가 있는 행을 지정
import pandas as pd
df = pd.read_excel('file.xls', header=2)
- (chatGPT가 알려준) 불필요한 Unnamed 컬럼 제거
import pandas as pd
df = pd.read_excel('file.xls')
df = df.loc[:, ~df.columns.str.contains('^Unnamed')]
- 수동으로 헤더 이름 지정
import pandas as pd
df = pd.read_excel('file.xls', header=None)
df.columns = ['결제일', '지출금액', '수입금액', '사용처', '은행/카드/증권사']
의외의 복병.. 날짜 형식
여러 개의 파일을 합치는 과정이다 보니 날짜 형식이 혼재해있었다.
- 2025년 01월 02일
- 2025-01-02
- 2025.01.02
만약 “2025년 01월 02일” 형식이 아닌 “2025년 1월 2일” 이라면 아래의 코드로 해결이 될 수도 있다.
import pandas as pd
df['결제일'] = pd.to_datetime(df['결제일'], format='mixed')
위의 코드로 해결되지 않는 경우 pandas에서 인식할 수 있는 날짜 형식이 아니라고 한다. 정규식이나 replace를 활용해서 날짜 형식을 일반화하는 것도 방법이다.
def normalizeDateFomat(date_str) :
if not isinstance(date_str, str) :
date_str = str(date_str)
if '년' in date_str and '월' in date_str and '일' in date_str :
return re.sub(r'(\d{4})년\s*(\d{1,2})월\s*(\d{1,2})일', r'\1-\2-\3', date_str)
elif '.' in date_str :
return date_str.replace('.', '-')
elif '/' in date_str :
parts = date_str.split('/')
if len(parts[2]) == 4 :
return f"{parts[2]}-{int(parts[0]):02}-{int(parts[1]):02}"
return date_str
짧은 회고
쉬울 것만 같았던 엑셀 가계부 만들기가 마냥 쉽지는 않았다. 아무래도 연달아 나타나는 오류도 한몫 한 것 같다. 데이터 형식도 다양하고, 원하는 방식으로 만들기 위해 어떤 것을 알아야 하는지 찾아보는 과정이 길었다. (아직도 전부를 아는 것이 아니다) 모르기 때문에 알아야 하는데 뭘 모르는지 모르는 단계이다. 그래도 pandas에서 지원하는 엑셀 관련 함수가 다양하고 모르는 내용은 구글에서 쉽게 검색할 수 있어서 일주일 동안 이만큼이라도 할 수 있었던 것 같다.
이번에는 개발을 빨리 결과물을 만들기 위해 데이터 전처리를 간소화 했는데 다음 v2.0에서는 이 부분을 조금 더 신경 써야겠다는 생각이 든다.
# TODO
- 테이블 사이에 빈 셀 추가
- 헤더별 색상 추가
- 총 수입, 항목란 추가
다음번에는 또 무슨 일이 일어날지 궁금하다.