feat. chatGpt와 함께 공부하는 파이썬 (인프런과 구글을 곁들인..)
~오류의 향연~
ValueError: Excel file format cannot be determined, you must specify an engine manually.
- 의미 : pandas에서 엑셀 파일 형식을 자동으로 파악하지 못함. xls인지 xlsx인지 모르겠음
- 오류 코드
import pandas as pd
pd.read_excel(filename)
- 해결1 (파일 확장자가 xls인 경우)
import pandas as pd
pd.read_excel(filename, engine='xlrd')
- 해결2 (파일 확장자가 xlsx인 경우)
import pandas as pd
pd.read_excel(filename, engine='openpyxl')
…
또 다른 오류 발생
ImportError: Missing optional dependency ‘lxml’. Use pip or conda to install lxml.
- 의미 : 해당 패키지가 없으니 설치하라는 의미
- 해결 (터미널에서 아래 명령어 수행, 둘 중에 사용하는 패키지 관리자만 수행)
- pip install lxml
- conda install lxml
ImportError: Missing optional dependency ‘html5lib’. Use pip or conda to install html5lib.
- 의미 : 동일
- 해결 (터미널에서 아래 명령어 수행, 둘 중에 사용하는 패키지 관리자만 수행)
- pip install html5lib
- conda install html5lib
[참고] Missing optional dependency ‘Package’ Use ‘Package Manager’ to install ‘Package’
- 이와 동일한 규칙을 가진 오류는 내용만 읽어봐도 대부분은 해결됩니다
- Package에 대한 의존성이 없으니 해당 Package를 설치하십시오
…
새로운 오류 발생
xlrd.biffh.XLRDError: Unsupported format, or corrupt file: Expected BOF record; found b’\r\n\r\n\r\n\r\n’
- 의미 : BOF가 알 수 없는 문자(‘\r\n\r\n\r\n\r\n’)입니다. xls 파일이 맞나요?
- 사전 지식
- BOF : Beginf Of File, 파일의 시작 문자, 시그니처 (파일별로 시작 문자가 다릅니다)
- ‘\r\n\r\n\r\n\r\n’ 는 아무런 내용이 없는, 파일 자체가 공백이거나 파일의 시작 내용이 공백이거나 html 파일의 개행 문자입니다
- 해결
import pandas as pd
# 오류 발생 코드
pd.read_excel(filename, engine='xlrd')
# 해결 코드
pd.read_html(filename, encoding='utf8')
트러블슈팅 과정
파이썬으로 엑셀 가계부를 만들고 있다. 카드사에서 내려받은 엑셀 파일이 구형 엑셀 버전인 xls이다. 파이썬 함수를 기본형으로만 사용했더니 간과했던 사실이 있다.
- 파일 확장자만 엑셀 형식인 경우
실무에서 엑셀 내려받기를 만들다 보면 경험할 수 있는데, 파일 확장자만 엑셀 형식이고 실제로는 html로 구현하는 경우가 있다. 이 경우에는 파일을 열었을 때 ‘~ 파일의 파일 형식 및 확장명이 일치하지 않습니다. 파일이 손상되었거나 안전하지 않을 수 있습니다. 데이터 원본을 신뢰하지 않는다면 파일을 열지 마세요. 그래도 파일을 겨시겠습니까?’ 라는 문구가 나온다.

이런 파일을 pandas.read_excel로 열 때 xlrd.biffh.XLRDError: Unsupported format, or corrupt file: Expected BOF record; found b’\r\n\r\n\r\n\r\n’ 오류가 발생했다. xls 형식이라고 알려줘서 xls 형식으로 읽으려고 했는데 파일의 시작 문자가(BOF) xls 형식이 아니라는 의미이다.
이럴 때는 engine을 명시 해줘야 한다.
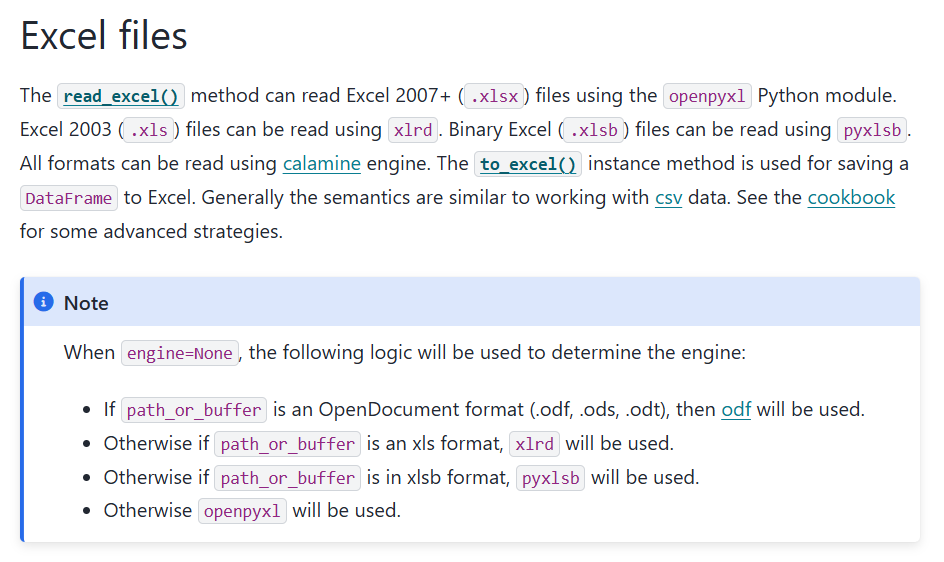
read_excel 파라미터, engine 짚고 넘어가기
pandas 공식 문서에 의하면 read_excel 함수를 사용할 때 engine=None은 아래와 같은 순서로 파일 읽기를 시도한다고 한다.
- odf → xlrd → pyxlsb → openpyxl → 읽을 수 없음
엑셀과 html의 BOF
해당 내용은 chatGPT의 답변 내용을 확인 후 수정한 표입니다.
| 확장자 | 시작 시그니처 (BOF) | 설명 |
|---|---|---|
.xls (바이너리) |
b'\xd0\xcf\x11\xe0\xa1\xb1\x1a\xe1' |
OLE2 Compound Format (MS 오피스 구버전 형식) read_excel(filename, engine=’xlrd’) |
.xlsx (XML 기반) |
b'PK\x03\x04' |
ZIP 포맷 (압축된 XML) read_excel(filename, engine=’openpyxl) |
.csv |
일반 텍스트 | 따로 시그니처 없음 read_csv(filename) |
.xls인데 HTML로 저장된 경우 |
b'<!DOCTYP...' 또는 b'<html' |
HTML 문서 시작 read_html(filename, encoding=’utf8’) |
.xlsx로 위장한 경우 |
b'<html' 또는 다른 형식 |
잘못된 확장자 read_html(filename, encoding=’utf8’) |
HTML |
일반 텍스트로 보통 다음 내용으로 시작함 • <!DOCTYPE html>• <html>• <head> 등 |
read_html(filename, encoding=’utf8’) |
결론
여러 카드사에서 내려받은 엑셀 파일을 읽어올 때 잘 열리는 파일, 오류가 발생하는 파일이 섞여있다. 확장자는 xls지만 BOF가 안 맞아 html 개행문자가 들어간 경우 read_html 함수를 사용해 파일 읽기를 수행하고, 실제로 xls인 경우 read_excel 함수를 이용해야 한다. 실제 확장자를 xlsx로 바꾼 후 read_excel 해야 데이터를 관리하기에 용이하다.
(복잡하지 않은 표만 있다면 read_html을 사용해도 괜찮겠으나, 귀찮은 것을 좋아하는 개발자에게만 추천합니다.)
실제 파일의 확장자를 xlsx로 바꿔주면 코드는 간결해지지만 나는 자동화를 원한다. read_html로 읽지 않고 해당 파일을 xlsx로 바꾼 뒤 read_excel 해도 된다는데 그것도 귀찮다.
추가
read_html로 엑셀을 읽었을 때 발생할 수 있는 문제
- 컬럼 헤더 꼬임
- 불필요한 행
- 병합 셀 인식
- pandas에서 제공하는 엑셀 관련 함수 사용 불가 (sheet_name 지정 불가)
권장 방식 : xls 또는 xlsx 로 변환 후 read_excel로 읽기
아래 함수로 오류를 피할 수 있었다.
import pandas as pd
# (수정) Exception 부분 수정정
# 엑셀 파일 열기
def openFile(filename):
ext = filename.split('.')[-1].lower()
try:
if ext == 'xls':
return pd.read_excel(filename, engine='xlrd')
elif ext == 'xlsx' :
# (수정) encoding 인자 없음
# return pd.read_excel(filename, engine='openpyxl', encoding='utf-8-sig')
return pd.read_excel(filename, engine='openpyxl')
# html 형식으로 읽기
# except Exception :
# return pd.read_html(filename, encoding='utf8')
# xlsx로 변환 후 읽기
except Exception :
temp_file = pd.read_html(filename, encoding='utf8')
df = temp_file[0] # DataFrame 형태로 바꾸기기
df.to_excel(filename+'x', index=False, engine='openpyxl')
return pd.read_excel(filename+'x', engine='openpyxl')